RPC(大点数脉冲压缩算法)
1. 概述
本文将以基于 FT04-DSP 的 rpc 算法的移植为例,介绍 AI+DSP 应用开发的开发流程。
算法简介:
大点数脉冲压缩(Pulse Compression)是雷达信号处理中的关键技术,该算法通过匹配滤波将宽脉冲信号压缩成窄脉冲,能够提高雷达的距离分辨率和检测能力,广泛用于气象雷达、合成孔径雷达、医学成像、地震勘探等需要处理超大点数信号的领域。
2. FT04 c实现
主要代码如下
void main(void)
{
int ID = getcoreid();
int iCntI, iCntJ; /**循环计数*/
int mask = 15; // 核掩码,低四位有效,0表示核0执行,3表示核0、核1执行,mask表示四个核执行
int iHeaderCPLX = 2048 / 8; /**回波协议*/
int iReadLenPerCore, iReadStPerCore, iWriteLenPerCore, iWriteStPerCore;
int iFillZeroLen;
int iPingPongFlag = 0;
int iChannelNum = 5; /**总波束个数,也就是通道个数*/
int iImageValidRLen = 43456; /**距离向有效点数*/
int iRSampleLen = 43456; /**距离向采样长度*/
int iASampleLen = 17; /**方位向收数点数*/
int iRpcLength = 65536; /**脉压结果长度*/
int iTpADNum; /**脉冲宽度Tp内的采样点数*/
float fFs = 25; /**采样率MHz*/
float fTp = 210; /**脉冲宽度us*/
float fKr = 20.2775 / 210; /**调频斜率*/
float fLosVel = 1.485044537103641e+03; /**平台和目标沿雷达视线的速度分量,单位m/s*/
float fPRT = 2.38092e+03; /**发射脉冲重复间隔,单位us*/
float fDr = 5.99584916; /**距离单元宽度*/
float fTemp0;
float r, theta;
iTpADNum = (int)(fFs * fTp + 0.5); /**脉冲宽度Tp内的采样点数*/
iReadLenPerCore = iRSampleLen >> 2;
iReadStPerCore = iReadLenPerCore * ID;
iWriteLenPerCore = iImageValidRLen >> 2;
iWriteStPerCore = iWriteLenPerCore * ID;
iFillZeroLen = iRpcLength - iRSampleLen;
CPLX *pcDDRfftTwid = (CPLX *)0x140000000; /**旋转因子 需要多少地址空间?*/
CPLX *pcDDRifftTwid = (CPLX *)0x180000000; /**旋转因子 需要多少地址空间?*/
float *pfGSMAngle = (float *)0x70320000;
CPLX *pcGSMData1 = (CPLX *)(0x70330000);
CPLX *pcGSMData2 = (CPLX *)(0x703b0000);
CPLX *pcGSMfftBuf = (CPLX *)(0x70200000); /**算子缓存地址,所需空间为数据量的2倍,计算后释放*/
CPLX *pcGSMBuf = (CPLX *)(0x703a0000); /**缓存地址*/
CPLX *pcGSMRefBuf = (CPLX *)(0x70760000); /**运动补偿系数(方位线)缓存地址*/
CPLX *pcGSMPcRef = (CPLX *)(0x70430000); /**参考函数*/
CPLX *pcGSMRcRef = (CPLX *)(0x704b0000); /**运动补偿系数*/
CPLX *pcGSMRef = (CPLX *)(0x70730000); /**运动补偿系数*/
CPLX *pcGSMDataIn[2];
CPLX *pcGSMDataOut[2];
CPLX *pcDDRDataIn = (CPLX *)(0x80000000); /**原始回波存储地址*/
CPLX *pcDDRDataOut = (CPLX *)(0x100000000); /**结果存储地址*/
int *piGSMBuf = (int *)(0x70780000);
pcGSMDataIn[0] = (CPLX *)(0x70530000);
pcGSMDataIn[1] = (CPLX *)(0x705b0000);
pcGSMDataOut[0] = (CPLX *)(0x70630000);
pcGSMDataOut[1] = (CPLX *)(0x706b0000);
unsigned long long cnt, cnt1, Use_Time, cnt2, cnt3, Use_Time1, cnt4, cnt5, Use_Time2, cnt6, cnt7, cnt8, Use_Time3, Use_Time4, Use_Time5, Use_Time6, Use_Time7;
setTimerPeriod(0xffffffff); // 配置定时器周期0xffffffff
configTimer(0x80); // 持续性计数,定时器当计数等于周期后一个时钟周期,计数重置为0再重新计数
asm("smfence\t");
timerStart(0);
asm("smfence\t");
sys_bar(0, 4);
cnt = getTimerCount();
int i;
float *p;
/**旋转因子初始化*/
gk_getw_core((CPLX *)pcDDRfftTwid, iRpcLength, 0, mask);
sys_bar(0, 4);
gk_getw_core((CPLX *)pcDDRifftTwid, iRpcLength, 1, mask);
sys_bar(0, 4);
/**计算脉压系数*/
get_angle_f_core(fFs, fKr, iTpADNum, pfGSMAngle, mask);
sys_bar(0, 4);
gk_cos_sin_f_core(pfGSMAngle, iTpADNum, pcGSMData1, mask);
sys_bar(0, 4);
gk_cvmemfill_f_core(0, 0, iRpcLength - iTpADNum, pcGSMData1 + iTpADNum, mask);
sys_bar(1, 4);
gk_getw_core((CPLX *)pcDDRfftTwid, iRpcLength, 0, mask);
sys_bar(0, 4);
gk_FFT_core((CPLX *)pcGSMData1, (CPLX *)pcDDRfftTwid, (CPLX *)pcGSMData2, iRpcLength, (CPLX *)pcGSMfftBuf, mask); /**FFT*/
sys_bar(12, 4);
gk_bitrev_core((float *)pcGSMData2, iRpcLength, (float *)pcGSMPcRef, (float *)pcGSMfftBuf, mask); /**反序 输出为pcGSMRef*/
sys_bar(3, 4);
gk_cvconj_f_core((float *)pcGSMPcRef, iRpcLength, (float *)pcGSMPcRef, mask);
sys_bar(4, 4);
gk_cvmemfill_f_core(1, 0, iRpcLength, pcGSMRcRef, mask);
sys_bar(0, 4);
/**运动补偿初始化*/
gk_cvmemfill_f_core(0, 1, iASampleLen, pcGSMRefBuf, mask);
sys_bar(0, 4);
fTemp0 = -fLosVel * fPRT * 1e-6 / fDr / iRpcLength; /**(velLos*prt*(noPulse-1)+rangeComp/2)/widthRange/numFFT*/
gk_tmuls_f_4core(-(iASampleLen - 1) / 2.0, fTemp0, iASampleLen, (float *)pcGSMBuf); /**rcCoef=exp(1j * 2 * pi * (-losVel*pri*((0:(prNum-1))-(prNum-1)/2)/disWidth)/range_fftNum);*/
sys_bar(0, 4);
gk_vej_f_4core((float *)pcGSMBuf, pcGSMBuf, iASampleLen, pcGSMRefBuf);
sys_bar(0, 4);
/**这一块因为没有直接求int型向量的函数,所以用了两步*/
gk_tmuls_f_4core(-iRpcLength / 2, 1, iRpcLength, pcGSMRcRef); /**生成距离向向量*/
sys_bar(0, 4);
gk_vmuls_i_core(pcGSMRcRef, 1, iRpcLength, piGSMBuf, 15); /**需要int型(做转换)*/
sys_bar(0, 4);
/**读取单条脉冲单个通道的数据*/
pcDDRDataIn = pcDDRDataIn + iHeaderCPLX;
DMA_Config(6, pcDDRDataIn + iReadStPerCore, pcGSMDataIn[iPingPongFlag] + iReadStPerCore, 0, 0, iReadLenPerCore, 8);
DMA_start(0x40);
DMA_check(0x40);
sys_bar(0, 4);
pcDDRDataIn = pcDDRDataIn + iRpcLength; // 源数据通道间隔为65536
cnt1 = getTimerCount();
Use_Time = (cnt1 - cnt) * 20;
for (iCntJ = 0; iCntJ < iASampleLen; iCntJ++) /***/
{
Use_Time1 = 0;
Use_Time2 = 0;
sys_bar(0, 4);
cnt2 = getTimerCount();
r = sqrt(pcGSMRefBuf[iCntJ].re * pcGSMRefBuf[iCntJ].re + pcGSMRefBuf[iCntJ].im * pcGSMRefBuf[iCntJ].im);
theta = atan(pcGSMRefBuf[iCntJ].im / pcGSMRefBuf[iCntJ].re);
gk_cvpown_f_core(r, theta, iRpcLength, piGSMBuf, pcGSMData2, mask);
sys_bar(0, 4);
DMA_Config(0, pcGSMData2 + iRpcLength / 8 * ID, pcGSMRcRef + iRpcLength / 2 + iRpcLength / 8 * ID, 0, 0, 0x8000, 2); /**做一下fftshift*/
DMA_Config(1, pcGSMData2 + iRpcLength / 2 + iRpcLength / 8 * ID, pcGSMRcRef + iRpcLength / 8 * ID, 0, 0, 0x8000, 2);
DMA_start(3);
DMA_check(3);
sys_bar(0, 4);
cnt3 = getTimerCount();
Use_Time1 = (cnt3 - cnt2) * 20 + Use_Time1;
for (iCntI = 0; iCntI < iChannelNum; iCntI++) /***/
{
if (iCntI == (iChannelNum - 1))
{
pcDDRDataIn = pcDDRDataIn + iHeaderCPLX;
}
sys_bar(0, 4);
iPingPongFlag = ((iCntJ * iChannelNum) + iCntI + 1) % 2;
/**读取单条脉冲单个通道的数据*/
DMA_Config(6, pcDDRDataIn + iReadStPerCore, pcGSMDataIn[iPingPongFlag] + iReadStPerCore, 0, 0, iReadLenPerCore, 8);
DMA_start(0x40);
iPingPongFlag = ((iCntJ * iChannelNum) + iCntI) % 2;
gk_cvmemfill_f_core(0, 0, iFillZeroLen, pcGSMDataIn[iPingPongFlag] + iRSampleLen, mask);
sys_bar(0, 4);
gk_FFT_core((CPLX *)pcGSMDataIn[iPingPongFlag], (CPLX *)pcDDRfftTwid, (CPLX *)pcGSMData2, iRpcLength, (CPLX *)pcGSMfftBuf, mask); /**FFT*/
sys_bar(0, 4);
gk_bitrev_core((float *)pcGSMData2, iRpcLength, (float *)pcGSMData1, (float *)pcGSMfftBuf, mask); /**反序 输出为pcGSMRef*/
sys_bar(0, 4);
gk_cvmulcv_f_core(pcGSMData1, pcGSMRcRef, iRpcLength, pcGSMData1, mask); /**乘运动补偿*/
sys_bar(0, 4);
gk_cvmulcv_f_core(pcGSMData1, pcGSMPcRef, iRpcLength, pcGSMData1, mask); /**乘脉压系数*/
sys_bar(0, 4);
gk_IFFT_core((CPLX *)pcGSMData1, (CPLX *)pcDDRfftTwid, (CPLX *)pcGSMData2, iRpcLength, (CPLX *)pcGSMfftBuf, mask); /**FFT*/
sys_bar(0, 4);
gk_bitrev_core((float *)pcGSMData2, iRpcLength, (float *)pcGSMDataOut[iPingPongFlag], (float *)pcGSMfftBuf, mask); /**反序 输出为pcGSMRef*/
sys_bar(0, 4);
/**存储单条脉冲单个通道的数据*/
if (((iCntJ * iChannelNum) + iCntI) > 0)
{
DMA_check(0x80);
}
DMA_Config(7, pcGSMDataOut[iPingPongFlag] + iWriteStPerCore, pcDDRDataOut + iWriteStPerCore, 0, 0, iWriteLenPerCore, 8);
DMA_start(0x80);
sys_bar(0, 4);
pcDDRDataIn = pcDDRDataIn + iRpcLength; // 源数据通道间隔为65536
pcDDRDataOut = pcDDRDataOut + iImageValidRLen;
DMA_check(0x40);
cnt4 = getTimerCount();
Use_Time2 = (cnt4 - cnt3) * 20 + Use_Time2;
}
}
DMA_check(0x80);
if (ID == 0)
{
printf("ok\n\n");
}
}
本代码用 FT-IDE 编译,能在ft04 板卡上加载、运行。
部分接口介绍:
sys_bar为栅栏接口,用于多核同步:只有当所有核都完成当前计算任务后,才会开启下一个计算任务。getTimerCount为时钟接口,它返回当前时钟的节拍数:用于性能统计。DMA_Config为DMA传输接口,用于提升数据的搬移的速度。gk_开头的函数为具体的 dsp 算子,算子的功能可通过查阅相关文档、头文件、代码可知,本文就不逐一介绍。
3. 开发流程
3.1 数据导入
c实现中,数据读取是通过IDE导入的。在python中使用 open 函数打开并读取原始的二进制数据文件,并把其转成complex64类型的复数tensor。
示例代码:
with open("data_43456_17_rpcdata_chnum5_RPCDataIn.bin", 'rb') as f:
raw_data = f.read()
echo = np.frombuffer(raw_data, dtype=np.complex64)
echo = Tensor(echo)
3.2 常量处理
移植时的主要工作是:将 c 算子的计算逻辑转换为 MindSpore Signal+ 的 API 调用。
整体分析可知,从数据导入到内层循环的fft之前的步骤,主要是模型常量的生成,另外乘法算子
gk_cvmulcv_f_core(pcGSMData1, pcGSMRcRef, iRpcLength, pcGSMData1, mask); /**乘运动补偿*/
sys_bar(0, 4);
gk_cvmulcv_f_core(pcGSMData1, pcGSMPcRef, iRpcLength, pcGSMData1, mask); /**乘脉压系数*/
中的 pcGSMRcRef、pcGSMPcRef 均为长度为 65536 的一维数据,其生成只依赖于给定的参数,不依赖于原始输入,为模型中的常量。
为避免额外的开销,可将其相乘后放在__init__中。
示例代码:
class rpc(nn.Cell):
def __init__(self):
super(rpc, self).__init__()
fFs = 25
fTp = 210
fKr = 20.2775 / 210
iTpADNum = (int)(fFs * fTp + 0.5)
iRpcLength = 65536
...
3.3 核心计算
循环部分是算法的核心,其主要流程是在循环中对一维的数据做fft、乘法和ifft运算。
可使用下列优化方法来提升性能:
维度提升:因为框架中算子:fft、乘法和ifft均支持二维输入,所以把核心中的一维算子、数据改写成二维的,这样可节省框架的循环调用的开销。
gk_FFT_core((CPLX *)pcGSMDataIn[iPingPongFlag], (CPLX *)pcDDRfftTwid, (CPLX *)pcGSMData2, iRpcLength, (CPLX *)pcGSMfftBuf, mask); /**FFT*/
中的 pcGSMDataIn 为长度为 65536 的一维输入数据,可把其当成一个二维输入 tensor 中的一行。
gk_bitrev_core((float *)pcGSMData2, iRpcLength, (float *)pcGSMDataOut[iPingPongFlag], (float *)pcGSMfftBuf, mask); /**反序 输出为pcGSMRef*/
中的 pcGSMDataOut 为长度为 65536 的一维输出数据,可把其当成一个二维输出 tensor 中的一行。
空间分配:在运行前为框架算子缓存区分配空间,并将存储类型设置为
smc,这样能提升算子的访存速度,对于此应用,使用smc前后运行时间分别为:88ms、70ms,性能提升了 18 ms。
示例代码:
def construct(self, t):
t = t.reshape(self.iASampleLen, t.size//self.iASampleLen)
t = self.slice(t, [0, self.iHeaderCPLX], [self.iASampleLen, self.iRpcLength*self.iChannelNum])
t = t.reshape(self.line, self.iRpcLength)
t = self.slice(t, [0,0], [self.line, self.iRSampleLen])
t = ops.cat((t, self.zero), 1)
t = self.fft(t)
t = self.mul(t, self.pcGSMRcRef)
t = self.ifft(t)
t = self.slice(t, [0,0], [self.line, self.iRSampleLen])
t = t.reshape(t.size)
return t
python完整代码示例:
import numpy as np
import mindspore as ms
import mindradar as mr
from mindspore import Tensor, ops, nn
import data_compare as compare
class rpc(nn.Cell):
def __init__(self):
super(rpc, self).__init__()
fFs = 25
fTp = 210
fKr = 20.2775 / 210
iTpADNum = (int)(fFs * fTp + 0.5)
iRpcLength = 65536
iRSampleLen = 43456
iASampleLen = 17
iChannelNum = 5
f_n = iRpcLength - iTpADNum
pfGSMAngle = np.zeros(iTpADNum, dtype=np.float32)
for i in range(iTpADNum):
tr = (i - iTpADNum / 2.0) / fFs
pfGSMAngle[i] = np.pi * fKr * tr * tr
pcGSMData1 = pfGSMAngle.astype(np.complex64)
pcGSMData1.real = np.cos(pfGSMAngle)
pcGSMData1.imag = np.sin(pfGSMAngle)
zero = np.zeros(f_n, dtype=np.complex64)
pcGSMData1 = np.append(pcGSMData1, zero, axis=0)
pcGSMPcRef = np.fft.fft(pcGSMData1).astype(np.complex64)
pcGSMPcRef = np.conj(pcGSMPcRef)
tmuls_0 = -(iASampleLen - 1) / 2.0
fLosVel = 1.485044537103641e+03
fPRT = 2.38092e+03
fDr = 5.99584916
fTemp0 = -fLosVel * fPRT * 1e-6 / fDr / iRpcLength
pcGSMBuf = np.zeros(iASampleLen, dtype=np.float32)
for i in range(iASampleLen):
pcGSMBuf[i] = (tmuls_0 + i) * fTemp0
pcGSMRefBuf = pcGSMBuf.astype(np.complex64)
pcGSMRefBuf.real = np.cos(pcGSMBuf * 2 * np.pi)
pcGSMRefBuf.imag = np.sin(pcGSMBuf * 2 * np.pi)
piGSMBuf = np.linspace(-iRpcLength / 2, iRpcLength / 2 - 1, iRpcLength).astype(np.int32)
line = iASampleLen * iChannelNum
pcGSMData2 = np.zeros(line * iRpcLength, dtype=np.complex64).reshape(line, iRpcLength)
for j in range(iASampleLen):
for i in range(iChannelNum):
pcGSMData2[j * iChannelNum + i] = np.power(pcGSMRefBuf[j], piGSMBuf)
pcGSMRcRef = np.fft.fftshift(pcGSMData2, 1)
pcGSMRcRef = pcGSMRcRef * pcGSMPcRef
self.pcGSMRcRef = Tensor(pcGSMRcRef)
self.iASampleLen = iASampleLen
zero = np.zeros(line*(iRpcLength-iRSampleLen), dtype=np.complex64).reshape(line, iRpcLength-iRSampleLen)
self.zero = Tensor(zero)
self.iRpcLength = iRpcLength
self.iRSampleLen = iRSampleLen
self.iChannelNum = iChannelNum
self.line = line
self.iHeaderCPLX = 256
self.fft = mr.FFT()
self.ifft = mr.IFFT()
self.mul = ops.Mul()
self.slice = ops.Slice()
def construct(self, t):
t = t.reshape(self.iASampleLen, t.size//self.iASampleLen)
t = self.slice(t, [0, self.iHeaderCPLX], [self.iASampleLen, self.iRpcLength*self.iChannelNum])
t = t.reshape(self.line, self.iRpcLength)
t = self.slice(t, [0,0], [self.line, self.iRSampleLen])
t = ops.cat((t, self.zero), 1)
t = self.fft(t)
t = self.mul(t, self.pcGSMRcRef)
t = self.ifft(t)
t = self.slice(t, [0,0], [self.line, self.iRSampleLen])
t = t.reshape(t.size)
return t
with open("data_43456_17_rpcdata_chnum5_RPCDataIn.bin", 'rb') as f:
raw_data = f.read()
echo = np.frombuffer(raw_data, dtype=np.complex64)
echo = Tensor(echo)
fun = rpc()
out = fun(echo)
ms.export(fun, echo, file_name="rpc", file_format="MINDIR")
print('out', out.shape)
print('out', out)
out = out.asnumpy()
compare.data_compare(out, "out_43456_5_17.bin")
compare.data_compare(out, "rpc_model_out.bin")
4. 转换模型
在上述代码中,我们已经使用了 export 方法导出了rpc.mindir模型。 要将该模型部署到 FT04 平台,需要将 mindir 格式转换成 mindspore lite 的 ms 格式。
现使用 MindSpore 的转换工具:converter_lite 进行转换。
转换命令如下:
./converter_lite --fmk=MINDIR --modelFile=/mnt/hgfs/D/work/mind-radar/examples/rpc/rpc.mindir --outputFile=/mnt/hgfs/D/work/mind-radar/examples/rpc/rpc
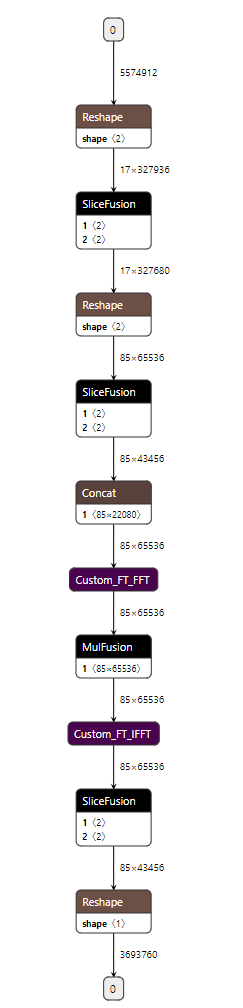
转换完成后,生成模型rpc.ms 后,可使用可视化工具:netron 打开模型,查看模型结构。
模型结构如图所示:
5. 端侧部署、运行
打开 YHFT-IDE ,新建工程。输入工程名、路径,工程类型选择 Heterogeneous , 输入交叉编译工具路径,然后点确定。会生成一个异构模板工程。
通过修改 data_handler.cc 文件中的函数来调整模型的输入数据,输入改成原始数据文件路径。
在 main 函数设置运行后端;修改 CMakeLists.txt 文件, 最后编译该工程,编译成功后将 build 文件夹下的可执行文件和模型 rpc.ms 一起拷贝到 FT04 中。
在FT04上运行可执行文件,观察输出结果。与预期结果对比,验证模型是否正确。
执行命令如下:
./mindspore_rpc rpc.ms
程序在执行时会打印部分输入输出数据,以及各部分的运行时间,并生成模型输出的数据文件rpc_model_out.bin,用于后续的验证、分析
。实测该模型的运行时间为 70 ms。
6. 测试
测试验证模型输出结果。
将数据文件rpc_model_out.bin 拷出来, 同标准结果out_43456_5_17.bin 进行比较。
运行结果比较的 python 代码。
compare.data_compare(out, "out_43456_5_17.bin")
compare.data_compare(out, "rpc_model_out.bin")
此处将 python 的输出结果依次与标准结果out_43456_5_17.bin 、模型输出结果rpc_model_out.bin进行比较。
python 输出与标准值的比较结果如下:


数据比较代码示例:
import numpy as np
def data_compare(input, file):
real = input.real.astype(np.float32)
imag = input.imag.astype(np.float32)
input = np.zeros(real.size * 2, dtype=np.float32)
for i in range(real.size):
input[2 * i] = real[i]
input[2 * i + 1] = imag[i]
print('input', input.shape)
print('input', input)
with open(file, 'rb') as f:
raw_data = f.read()
input1 = np.frombuffer(raw_data, dtype=np.float32)
print('input1', input1.shape)
print('input1', input1)
if input.size != input1.size:
raise ValueError(f"size: {input.size} != {input1.size}")
diff = np.abs(input1 - input)
diff1 = np.abs(diff/input1)
max = np.unravel_index(np.argmax(diff), input.shape)
max1 = np.unravel_index(np.argmax(diff1), input.shape)
# print('diff', diff.shape)
# print('diff', diff)
report = "误差分析:\n"
report += f" 最大绝对误差: {diff[max]:.6f}\n"
report += f" 实测值: {input[max]:.6f}\n"
report += f" 标准值: {input1[max]:.6f}\n"
report += f" 索引: {max}\n"
report += f" 平均误差: {np.mean(diff):.6f}\n"
report += f" 误差范围: [{np.min(diff):.6f}, {np.max(diff):.6f}]\n\n"
report += f" 最大相对误差: {diff1[max1]:.6f}\n"
report += f" 实测值: {input[max1]:.6f}\n"
report += f" 标准值: {input1[max1]:.6f}\n"
report += f" 索引: {max1}\n"
report += f" 平均相对误差: {np.mean(diff1):.6f}\n"
report += f" 相对误差范围: [{np.min(diff1):.6f}, {np.max(diff1):.6f}]\n\n"
report += "绝对误差分布直方图 (全范围):\n"
bins = np.linspace(0, diff[max], 11) # 10个区间
hist, _ = np.histogram(diff, bins=bins)
for i in range(len(bins)-1):
start = bins[i]
end = bins[i+1]
report += f" 误差区间 {start:.3f}-{end:.3f}: {hist[i]}个\n"
report += "\n相对误差分布直方图 (全范围):\n"
bins = np.linspace(0, 0.3, 31)
bins[19:30] = np.linspace(0.3, 1.3, 11)
bins[-1] = diff1[max1]
hist, _ = np.histogram(diff1, bins=bins)
for i in range(len(bins)-1):
start = bins[i]
end = bins[i+1]
report += f" 误差区间 {start:.3f}-{end:.3f}: {hist[i]}个\n"
print(report)
return